

A estas alturas, probablemente estés familiarizado con uno o más lenguajes de programación. Pero, ¿alguna vez te has preguntado cómo podrías crear tu propio lenguaje de programación? Y con eso quiero decir:
Un lenguaje de programación es cualquier conjunto de reglas que convierten cadenas en diferentes tipos de código fuente de máquina.
En resumen, un lenguaje de programación es simplemente un conjunto de reglas predefinidas. Y para que sean útiles, necesita algo que entienda estas reglas. Y estas cosas son compiladores, traductoresetc. Así que podemos definir algunas reglas y luego, para que funcione, podemos usar cualquier lenguaje de programación existente para crear un programa que pueda entender esas reglas, que será nuestro intérprete.
Compilador
El compilador convierte el código en código de máquina que el procesador puede ejecutar (por ejemplo, un compilador de C++).
traductor
El intérprete recorre el programa línea por línea y ejecuta cada comando.
¿Quiero probar? Trabajemos juntos para crear un lenguaje de programación súper simple que genere una salida morada en la consola. lo llamaremos Magenta.


Configurar nuestro lenguaje de programación
Usaré Node.js, pero puede usar cualquier idioma para seguir, el concepto seguirá siendo el mismo. Comencemos por crear index.js archivar y configurar las cosas.
class Magenta {
constructor(codes) {
this.codes = codes
}
run() {
console.log(this.codes)
}
}
// For now, we are storing codes in a string variable called `codes`
// Later, we will read codes from a file
const codes =
`print "hello world"
print "hello again"`
const magenta = new Magenta(codes)
magenta.run()Lo que estamos haciendo aquí es declarar una clase llamada MagentaEsta clase define e inicia un objeto que se encarga de registrar texto en la consola con cualquier texto que le proporcionemos a través de codes Y por ahora lo hemos definido codes variable directamente en el archivo con varios mensajes de «hola».


Bien, ahora necesitamos crear lo que se llama Lexer.
¿Qué es Lexer?
Bien, hablemos de inglés por un segundo. Toma la siguiente frase:
¿Cómo estás?
Aquí «cómo» es un adverbio, «eres» es un verbo y «tú» es un pronombre. Al final tenemos un signo de interrogación («?»). Podemos dividir cualquier oración o frase como esa en muchos componentes gramaticales en JavaScript. Otra forma en que podemos distinguir estas partes es dividirlas en pequeñas fichas. El programa que divide el texto en tokens es nuestro. Lexer.


Debido a que nuestro lenguaje es muy pequeño, solo tiene dos tipos de tokens, cada uno con un valor:
keywordstring
Podríamos usar una expresión regular para recuperar tokens de codes cadena, pero el rendimiento será muy lento. Un mejor enfoque es pasar por cada carácter de code cadenas y agarrar etiquetas. Así que vamos a crear un tokenize método en nuestro Magenta clase – que será nuestro Lexer.
código completo
class Magenta {
constructor(codes) {
this.codes = codes
}
tokenize() {
const length = this.codes.length
// pos keeps track of current position/index
let pos = 0
let tokens = []
const BUILT_IN_KEYWORDS = ["print"]
// allowed characters for variable/keyword
const varChars="abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_"
while (pos < length) {
let currentChar = this.codes[pos]
// if current char is space or newline, continue
if (currentChar === " " || currentChar === "n") {
pos++
continue
} else if (currentChar === '"') {
// if current char is " then we have a string
let res = ""
pos++
// while next char is not " or n and we are not at the end of the code
while (this.codes[pos] !== '"' && this.codes[pos] !== 'n' && pos < length) {
// adding the char to the string
res += this.codes[pos]
pos++
}
// if the loop ended because of the end of the code and we didn't find the closing "
if (this.codes[pos] !== '"') {
return {
error: `Unterminated string`
}
}
pos++
// adding the string to the tokens
tokens.push({
type: "string",
value: res
})
} else if (varChars.includes(currentChar)) { arater
let res = currentChar
pos++
// while the next char is a valid variable/keyword charater
while (varChars.includes(this.codes[pos]) && pos < length) {
// adding the char to the string
res += this.codes[pos]
pos++
}
// if the keyword is not a built in keyword
if (!BUILT_IN_KEYWORDS.includes(res)) {
return {
error: `Unexpected token ${res}`
}
}
// adding the keyword to the tokens
tokens.push({
type: "keyword",
value: res
})
} else { // we have a invalid character in our code
return {
error: `Unexpected character ${this.codes[pos]}`
}
}
}
// returning the tokens
return {
error: false,
tokens
}
}
run() {
const {
tokens,
error
} = this.tokenize()
if (error) {
console.log(error)
return
}
console.log(tokens)
}
}Si empezamos esto en la terminal con node index.jsnecesitamos ver una lista de tokens impresos en la consola.

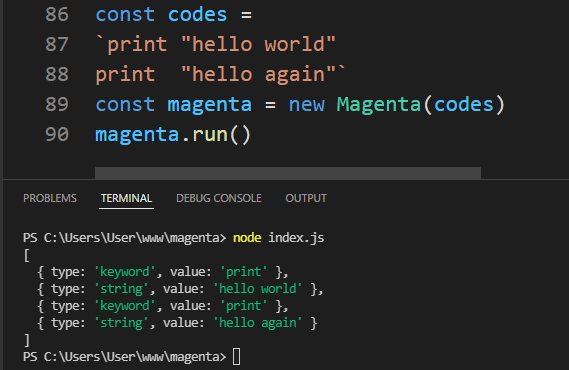
Definición de reglas y sintaxis
Queremos ver si el orden de nuestros códigos coincide con una regla o sintaxis. Pero primero necesitamos definir cuáles son estas reglas y sintaxis. Debido a que nuestro lenguaje es tan pequeño, solo tiene una sintaxis simple que es print palabra clave seguida de cadena.
keyword:print stringAsí que vamos a crear un parse un método que revisa nuestros tokens y ve si tenemos una sintaxis válida. De ser así, tomará las medidas necesarias.
class Magenta {
constructor(codes) {
this.codes = codes
}
tokenize(){
/* previous codes for tokenizer */
}
parse(tokens){
const len = tokens.length
let pos = 0
while(pos < len) {
const token = tokens[pos]
// if token is a print keyword
if(token.type === "keyword" && token.value === "print") {
// if the next token doesn't exist
if(!tokens[pos + 1]) {
return console.log("Unexpected end of line, expected string")
}
// check if the next token is a string
let isString = tokens[pos + 1].type === "string"
// if the next token is not a string
if(!isString) {
return console.log(`Unexpected token ${tokens[pos + 1].type}, expected string`)
}
// if we reach this point, we have valid syntax
// so we can print the string
console.log('x1b[35m%sx1b[0m', tokens[pos + 1].value)
// we add 2 because we also check the token after print keyword
pos += 2
} else{ // if we didn't match any rules
return console.log(`Unexpected token ${token.type}`)
}
}
}
run(){
const {tokens, error} = this.tokenize()
if(error){
console.log(error)
return
}
this.parse(tokens)
}
}Y mira eso, ¡ya tenemos un idioma de trabajo!
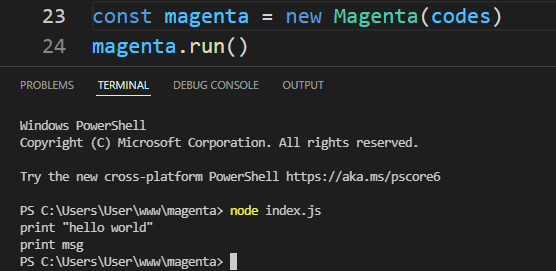

Está bien, pero tener códigos en una variable de cadena no es tan divertido. Así que pongamos lo nuestro Magenta códigos en un archivo llamado code.mDe esta manera podemos mantener nuestros códigos magenta separados de la lógica del compilador. .m como extensión de archivo para indicar que este archivo contiene código para nuestro idioma.
Leamos el código de este archivo:
// importing file system module
const fs = require('fs')
//importing path module for convenient path joining
const path = require('path')
class Magenta{
constructor(codes){
this.codes = codes
}
tokenize(){
/* previous codes for tokenizer */
}
parse(tokens){
/* previous codes for parse method */
}
run(){
/* previous codes for run method */
}
}
// Reading code.m file
// Some text editors use rn for new line instead of n, so we are removing r
const codes = fs.readFileSync(path.join(__dirname, 'code.m'), 'utf8').toString().replace(/r/g, "")
const magenta = new Magenta(codes)
magenta.run()¡Crea un lenguaje de programación!
Y con eso, creamos con éxito un pequeño lenguaje de programación desde cero. Verá, un lenguaje de programación puede ser tan simple como algo que logra una cosa a la vez. Por supuesto, es poco probable que un lenguaje como Magenta sea lo suficientemente útil como para ser parte de un marco popular o algo así, pero ahora ve lo que se necesita para crear uno.
El cielo es realmente el límite. Si desea profundizar un poco más, intente seguir este video, que hice mirando un ejemplo más extenso. Este es un video que también mostré, y puedes agregar variables a tu idioma.

