

Tuve que enviar varias veces HTTP solicitud con algunos datos de registro cuando un usuario hace algo como navegar a otra página o enviar un formulario. Considere este ejemplo ficticio de enviar información a un servicio externo cuando hace clic en un enlace:
<a href="https://css-tricks.com/some-other-page" id="link">Go to Page</a>
<script>
document.getElementById('link').addEventListener('click', (e) => {
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: "data"
})
});
});
</script>Nada terriblemente complicado está sucediendo aquí. Se permite que el enlace se comporte como de costumbre (no uso e.preventDefault()), pero antes de que ocurra este comportamiento, un POST se activa la solicitud clickNo es necesario esperar ninguna respuesta. solo quiero que me lo envien de cualquier servicio a acertar.
A primera vista, puede esperar que el envío de esta solicitud sea sincrónico, luego de lo cual continuaremos alejándonos de la página mientras otro servidor procesa esta solicitud con éxito. Pero resulta que esto no siempre sucede.
Los navegadores no garantizan que mantendrán abiertas las solicitudes HTTP
Cuando sucede algo que termina una página en el navegador, no hay garantía de que esté en progreso HTTP la solicitud será exitosa (ver más en «terminado» y otros estados del ciclo de vida en la página). La confiabilidad de estas solicitudes puede depender de varias cosas: la conexión de red, el rendimiento de la aplicación e incluso la configuración del propio servicio externo.
Como resultado, el envío de datos en estos momentos puede ser cualquier cosa menos confiable, lo cual es un problema potencialmente importante si confía en estos registros para tomar decisiones comerciales sensibles a los datos.
Para ilustrar esta falta de confiabilidad, configuré una pequeña aplicación Express con una página usando el código incluido arriba. Cuando se hace clic en el enlace, el navegador cambia a /otherpero antes de que eso suceda, un POST la solicitud fue rechazada.
Mientras esto sucede, tengo una sección «Red» abierta en el navegador y uso una velocidad de conexión «3G lenta». Una vez que la página se carga y borra la salida, las cosas parecen bastante tranquilas:


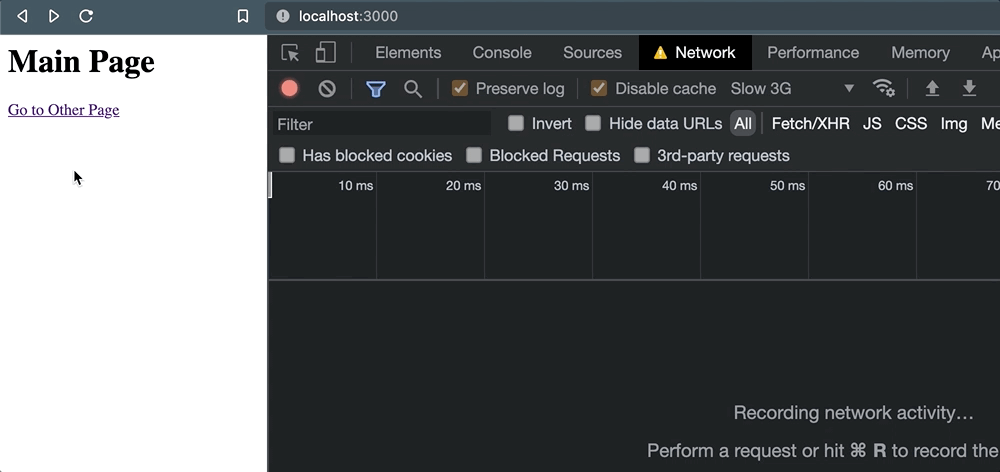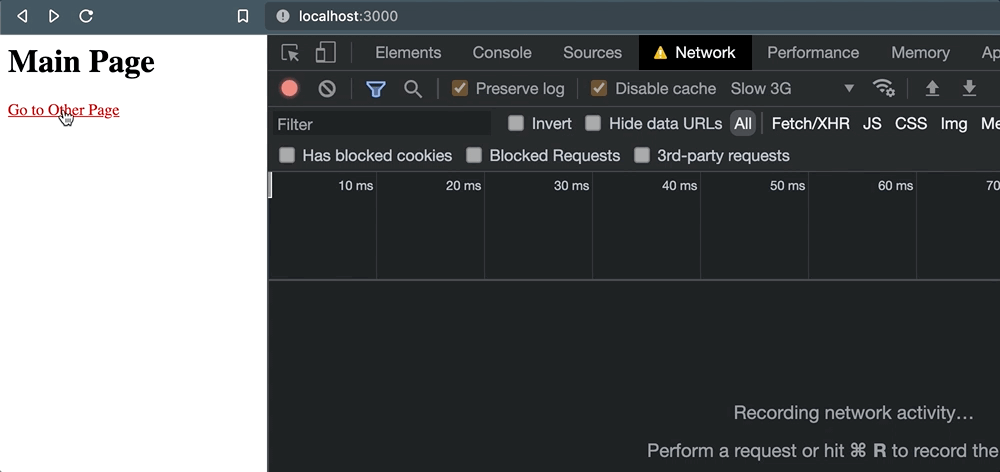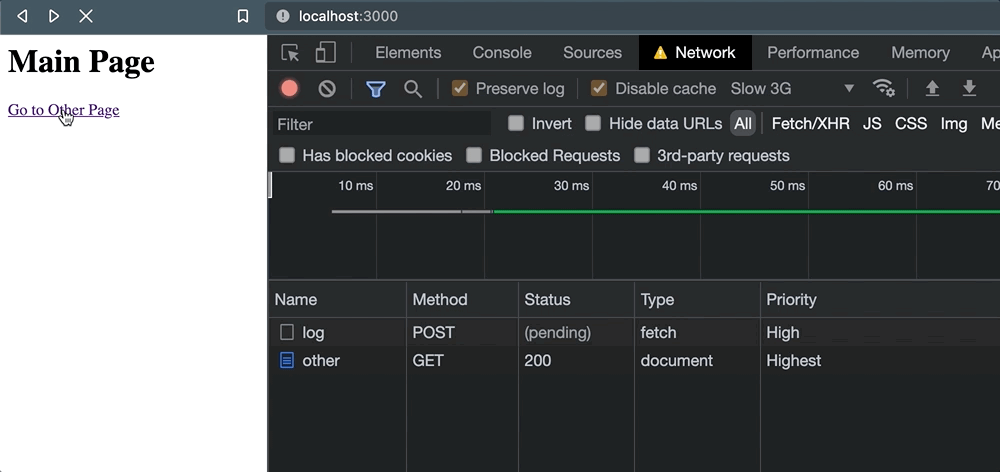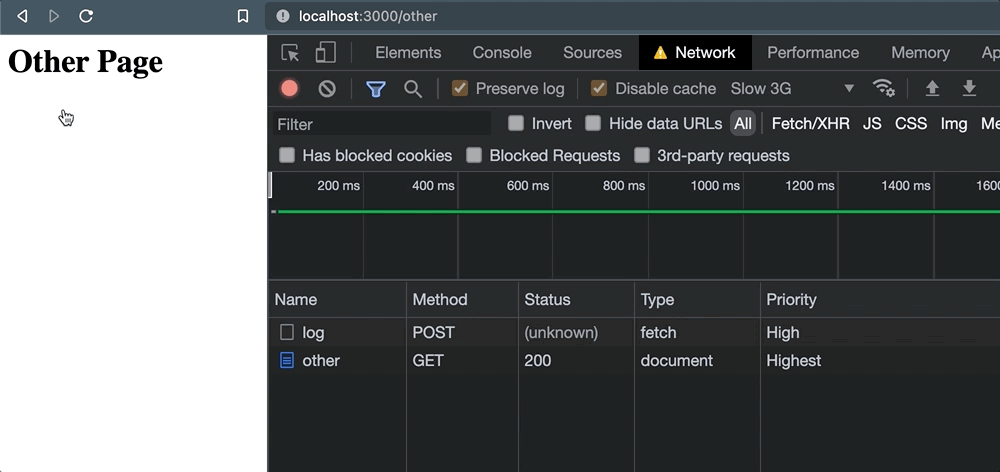
Pero tan pronto como se hace clic en el enlace, las cosas salen mal. Cuando aparece la navegación, la solicitud se cancela.
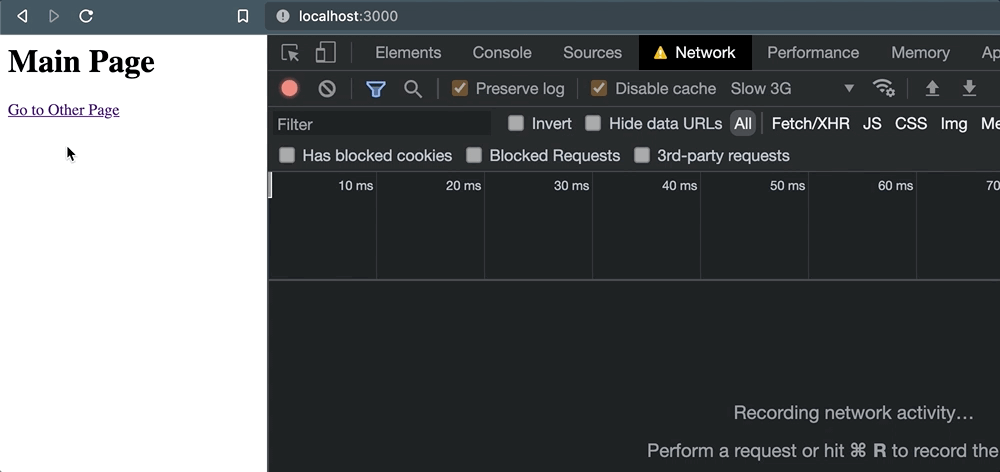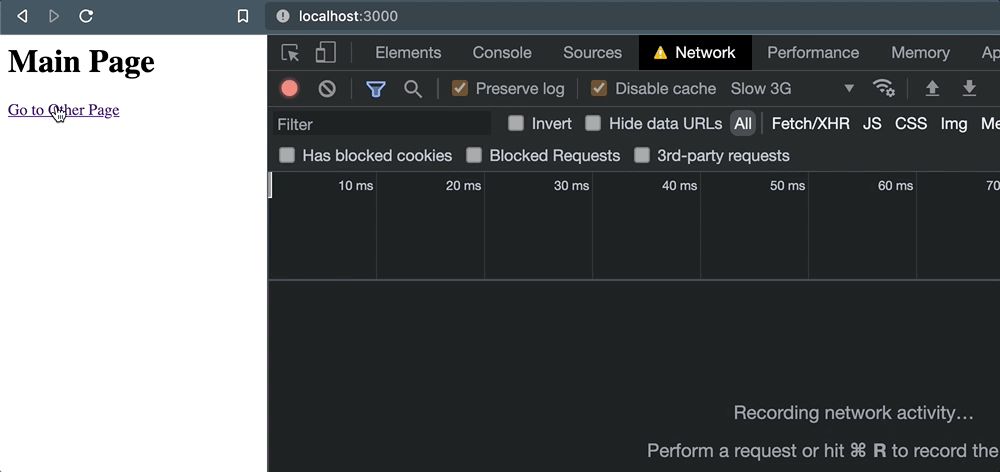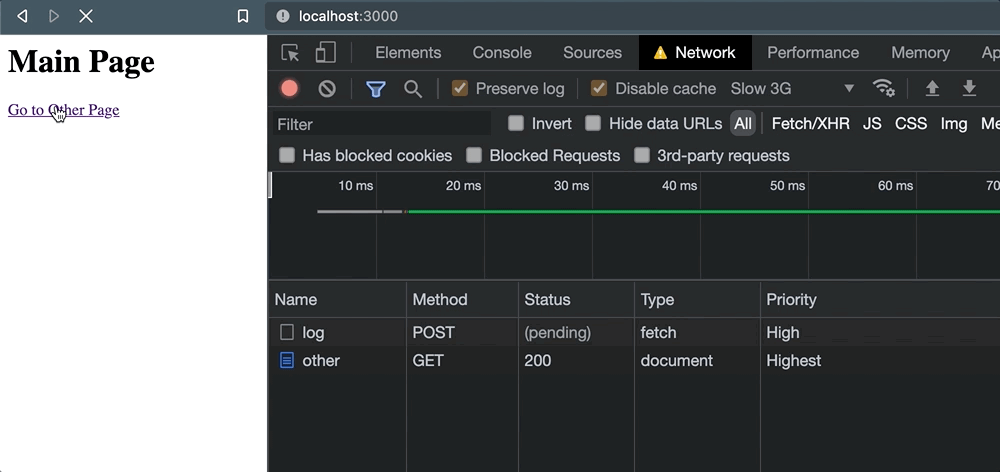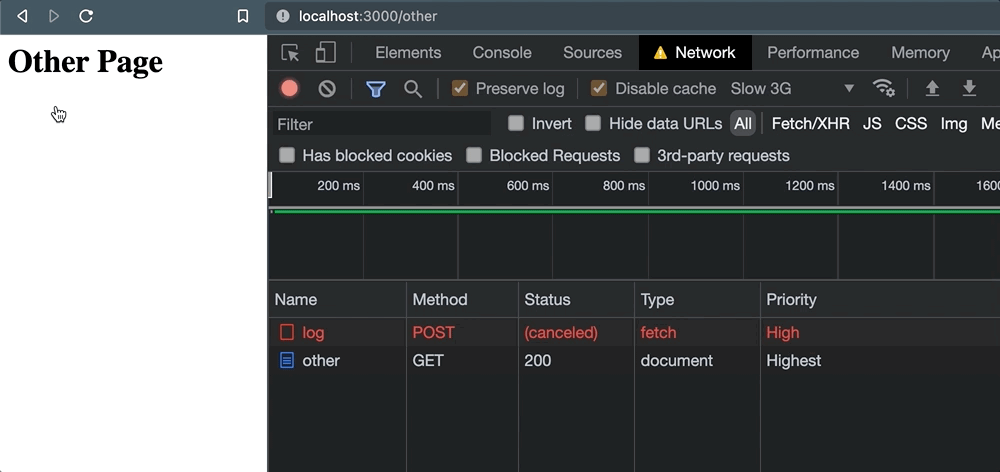
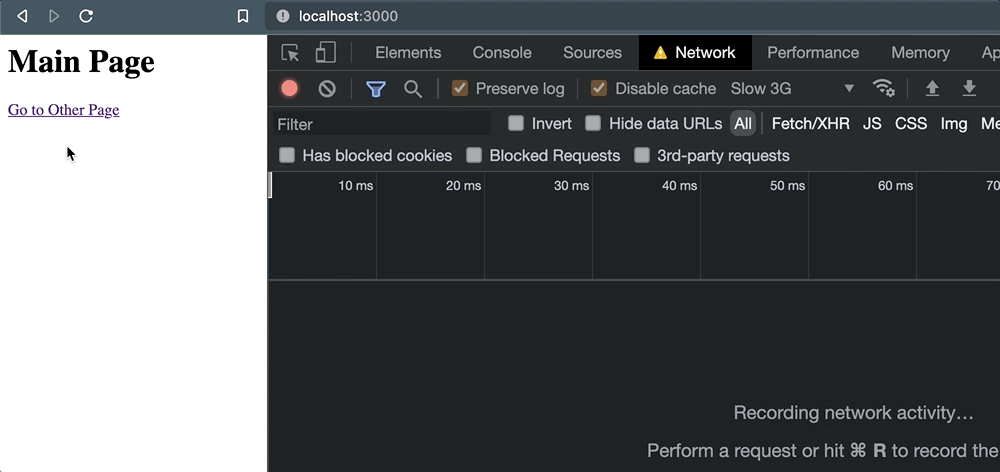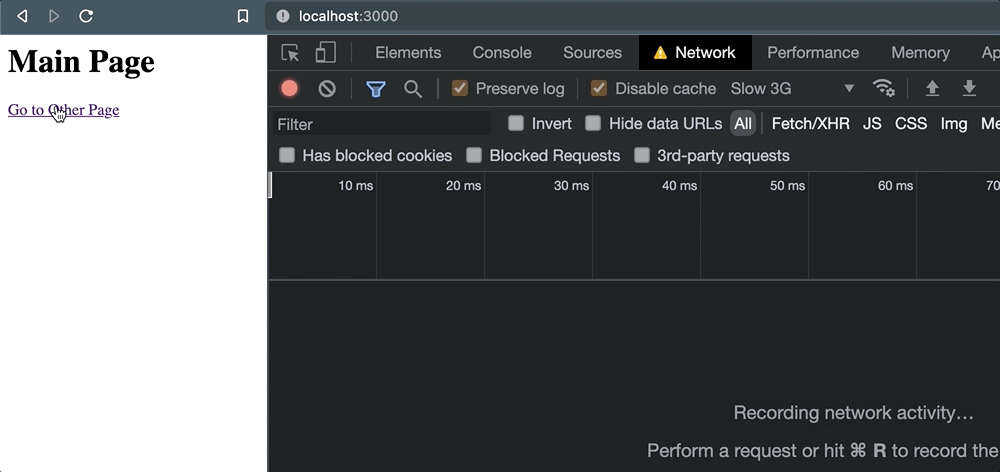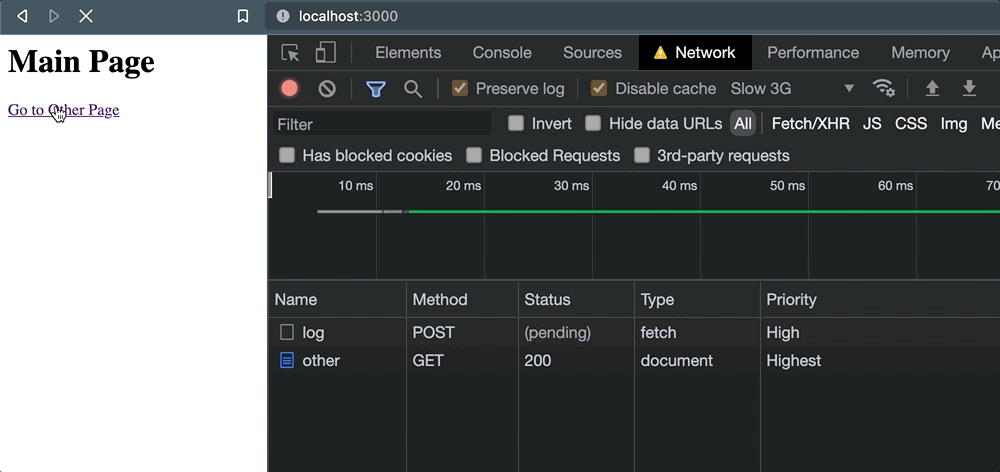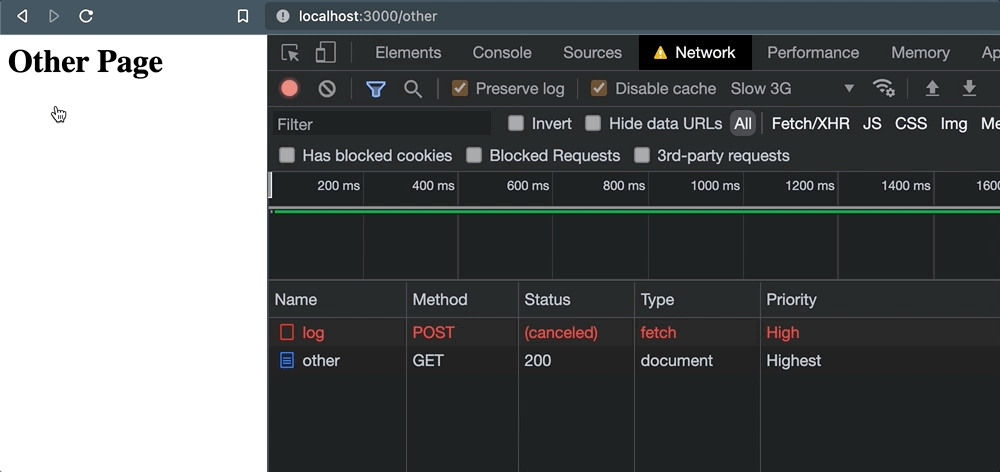
Y esto nos deja con poca confianza de que el servicio externo realmente haya logrado procesar la solicitud. Solo para comprobar este comportamiento, también sucede cuando navegamos programáticamente con window.location:
document.getElementById('link').addEventListener('click', (e) => {
+ e.preventDefault();
// Request is queued, but cancelled as soon as navigation occurs.
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: 'data'
}),
});
+ window.location = e.target.href;
});Independientemente de cómo o cuándo se realice la navegación y se cierre la página activa, estas solicitudes incompletas corren el riesgo de ser abandonadas.
Pero, ¿por qué se cancelan?
La raíz del problema es que las consultas XHR predeterminadas (a través de fetch o XMLHttpRequest) son asincrónicos y no bloqueantes Tan pronto como la solicitud está en la cola, la real trabajo la aplicación se transmite a la API en el nivel del navegador en segundo plano.
En términos de rendimiento, está bien: no desea que las consultas pasen el hilo principal. Pero también significa que existe el riesgo de que se abandonen cuando una página entre en este estado «terminado», lo que no deja ninguna garantía de que nada de esto esté detrás de escena. Así es como Google resume este estado particular del ciclo de vida:
La página finaliza después de que comienza a descargarse y borrar la memoria del navegador. No tareas nuevas puede ejecutarse en este estado y las tareas actuales pueden cancelarse si se ejecutan durante demasiado tiempo.
En resumen, el navegador está diseñado con la suposición de que cuando se rechaza una página, no necesita continuar procesando los procesos en segundo plano en cola.
¿Entonces, cuales son nuestras opciones?
Quizás el enfoque más obvio para evitar este problema es retrasar la acción del usuario tanto como sea posible hasta que la solicitud devuelva una respuesta. En el pasado, esto se hacía de manera incorrecta usando bandera síncrona apoyado desde dentro XMLHttpRequestPero su uso bloquea completamente el hilo principal, causando muchos problemas de rendimiento: escribí parte de eso en el pasado, por lo que la idea ni siquiera tiene que ser divertida. De hecho, está a punto de abandonar la plataforma (Chrome v80+ ya tiene lo eliminó).
En cambio, si va a tomar este tipo de enfoque, es mejor esperar un Promise para su resolución cuando se devuelva la respuesta. Una vez que regrese, puede realizar el comportamiento de manera segura. Usando nuestro fragmento de código anterior, esto podría verse así:
document.getElementById('link').addEventListener('click', async (e) => {
e.preventDefault();
// Wait for response to come back...
await fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: 'data'
}),
});
// ...and THEN navigate away.
window.location = e.target.href;
});Esto hace el trabajo, pero hay algunos defectos no triviales.
Primero, compromete la experiencia del usuario al ralentizar el comportamiento deseado. La recopilación de análisis es ciertamente buena para el negocio (y, con suerte, para los futuros usuarios), pero no es lo ideal para hacerlo. están presentes consumidores a pagar los costos de la realización de estos beneficios. sí sin mencionar que, como una dependencia externa, cualquier retraso u otro problema de rendimiento dentro del servicio en sí se le revelará al usuario. Si la latencia de su servicio de análisis hace que un cliente complete una acción de alto valor, todos pierden.
En segundo lugar, este enfoque no es tan confiable como parece inicialmente, ya que algunos comportamientos de finalización no se pueden posponer mediante programación. Por ejemplo, e.preventDefault() es inútil para ralentizar a alguien para cerrar una pestaña en el navegador. Así que, en el mejor de los casos, cubrirá la recopilación de datos para algunos acciones del usuario, pero no lo suficiente como para poder confiar en él por completo.
Indicar al navegador que guarde las solicitudes no cumplidas
Afortunadamente, hay opciones para salvar excepcional HTTP consultas integradas en la mayoría de los navegadores y que no requieren comprometer la experiencia del usuario.
Uso de Fetch keepalive bandera
Si keepalive bandera se establece en true cuando se usa fetch()la solicitud correspondiente permanecerá abierta incluso si se cierra la página que inició esta solicitud. Usando nuestro ejemplo original, esto hará una conversión que se ve así:
<a href="https://css-tricks.com/some-other-page" id="link">Go to Page</a>
<script>
document.getElementById('link').addEventListener('click', (e) => {
fetch("/log", {
method: "POST",
headers: {
"Content-Type": "application/json"
},
body: JSON.stringify({
some: "data"
}),
keepalive: true
});
});
</script>Cuando se hace clic en este enlace y aparece la navegación de la página, la solicitud no se cancela:
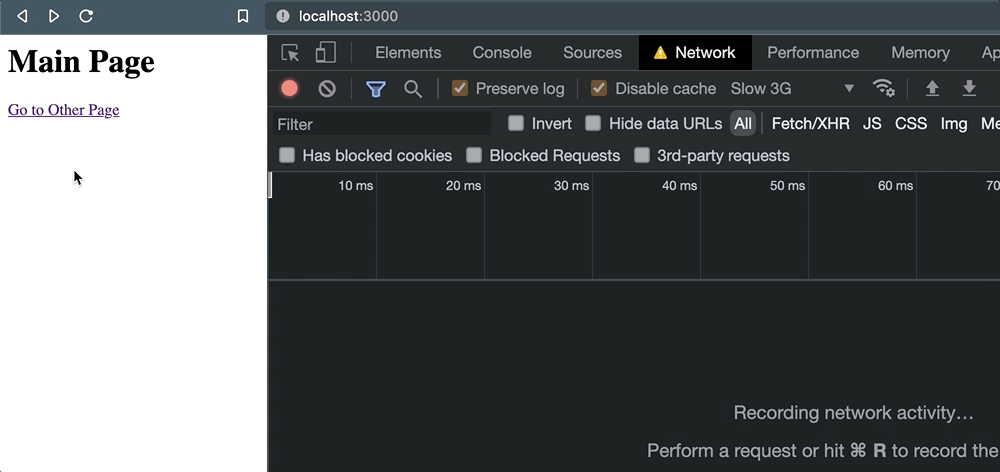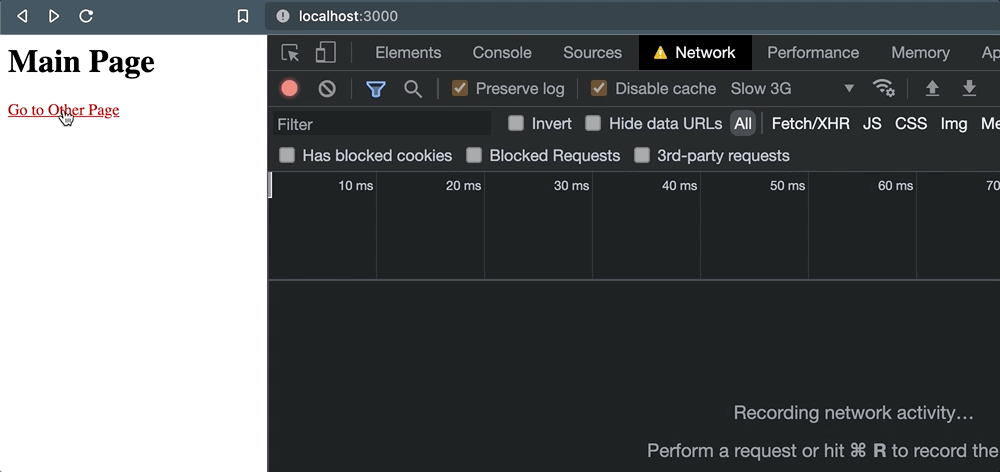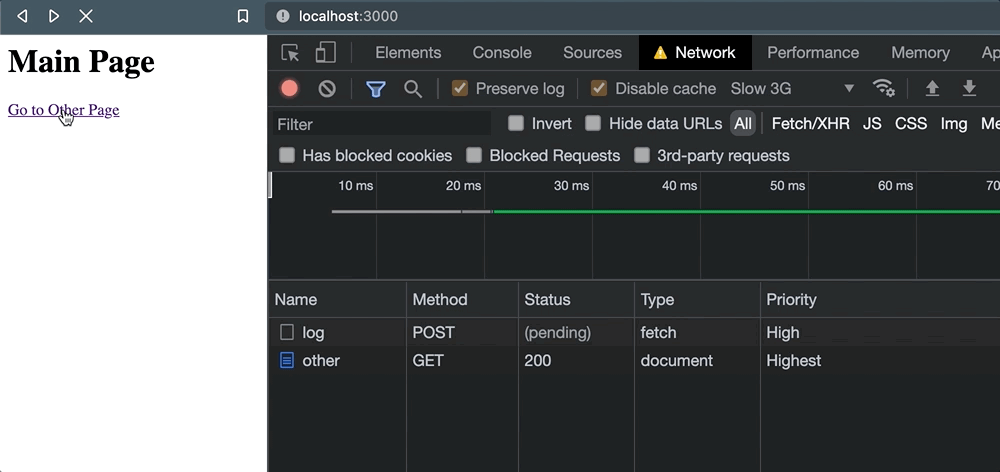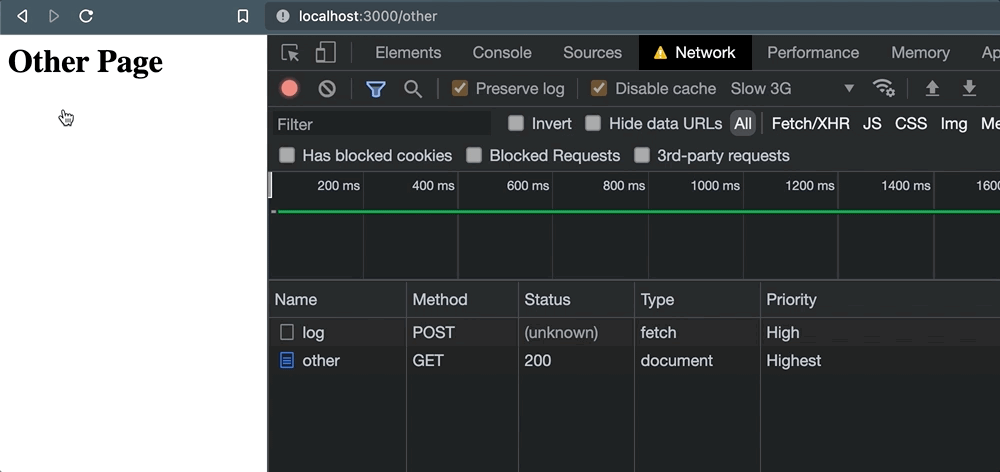
En cambio, nos quedamos con uno (unknown) estado simplemente porque la página activa nunca esperó una respuesta.
El texto de una línea como este es fácil de arreglar, especialmente cuando es parte de una API de navegador de uso común. Pero si está buscando una opción más enfocada con una interfaz más simple, hay otra forma con casi el mismo soporte de navegador.
Utilizando Navigator.sendBeacon()
EN Navigator.sendBeacon()la función está diseñada específicamente para enviar solicitudes unidireccionales (balizasUna conversión básica se ve así al enviar un POST con cadena JSON y «texto/simple» Content-Type:
navigator.sendBeacon('/log', JSON.stringify({
some: "data"
}));Pero esta API no le permite enviar encabezados personalizados. Entonces, para enviar nuestros datos como «aplicación / json», tendremos que hacer un pequeño ajuste y usar Blob:
<a href="https://css-tricks.com/some-other-page" id="link">Go to Page</a>
<script>
document.getElementById('link').addEventListener('click', (e) => {
const blob = new Blob([JSON.stringify({ some: "data" })], { type: 'application/json; charset=UTF-8' });
navigator.sendBeacon('/log', blob));
});
</script>Al final, obtenemos el mismo resultado: una consulta que se puede completar incluso después de navegar por la página. Pero hay algo más que puede darle una ventaja sobre fetch(): las balizas se envían con baja prioridad.
Para demostrarlo, esto es lo que aparece en la pestaña Red cuando ambos fetch() s keepalive y sendBeacon() se utilizan simultáneamente:


Por defecto, fetch() recibe una prioridad «alta», mientras que la baliza (marcada como «ping» arriba) tiene una prioridad «más baja». Para consultas que no son críticas para la funcionalidad de la página, está bien. Tomado directamente de la Especificación de baliza:
Esta especificación define una interfaz que […] Minimice las disputas de recursos con otras operaciones de tiempo crítico, al tiempo que garantiza que dichas solicitudes aún se procesen y entreguen en el destino.
En otras palabras, sendBeacon() asegura que sus aplicaciones se mantengan fuera del camino de aquellas que realmente importan para su aplicación y su experiencia de usuario.
mención de honor de ping atributo
Vale la pena mencionar que un número cada vez mayor de navegadores admiten ping Cuando se adjunta a las conexiones, activará pequeñas POST solicitud:
<a href="http://localhost:3000/other" ping="http://localhost:3000/log">
Go to Other Page
</a>Y estos encabezados de solicitud contendrán la página en la que se hace clic en el enlace (ping-from) así como también href valor de esta conexión (ping-to):
headers: {
'ping-from': 'http://localhost:3000/',
'ping-to': 'http://localhost:3000/other'
'content-type': 'text/ping'
// ...other headers
},Es técnicamente similar a una baliza de envío, pero tiene algunas limitaciones notables:
- Está estrictamente limitado al uso de enlaces, lo que hace que no sea la primera vez que necesite realizar un seguimiento de los datos relacionados con otras interacciones, como los clics en los botones o el envío de formularios.
- El soporte del navegador es bueno, pero no genial. En el momento de escribir este artículo, Firefox no lo ha habilitado específicamente de forma predeterminada.
- No puede enviar datos personalizados con la solicitud. Como mencionamos, lo máximo que obtendrá son unos pocos
ping-*encabezados, junto con todos los demás encabezados que están juntos para el viaje.
Teniendo en cuenta todas las cosas ping es una buena herramienta si eres bueno enviando consultas simples y no quieres escribir JavaScript personalizado. Pero si necesita enviar algo más sustancial, puede que no sea lo mejor para buscar.
Cuál Deber ¿alcanzar?
Definitivamente hay compensaciones en el uso de ambos fetch s keepalive o sendBeacon() para enviar sus solicitudes en el último segundo. Para averiguar qué es lo mejor para diferentes circunstancias, aquí hay algunas cosas que debe tener en cuenta:
puedes ir con fetch() + keepalive si:
- Debe enviar fácilmente encabezados personalizados con la solicitud.
- quieres hacer un
GETsolicitud de servicio, no unaPOST. - Admite navegadores más antiguos (como IE) y ya tiene un
fetchlos polófilos están cargados.
Pero sendBeacon() puede ser una mejor opción si:
- Realice solicitudes sencillas de servicios que no requieran mucha personalización.
- Prefiere una API más limpia y elegante.
- Desea asegurarse de que sus solicitudes no compitan con otras solicitudes de alta prioridad enviadas a la aplicación.
Evitar repetir mis errores
Hay una razón por la que elegí profundizar en la naturaleza de cómo los navegadores procesan las solicitudes en el proceso cuando se cierra una página. Mi equipo notó recientemente un cambio repentino en la frecuencia de un tipo específico de archivo de registro de análisis después de que comenzamos a activar la solicitud justo cuando se enviaba el formulario. El cambio fue repentino y significativo: aproximadamente una caída del 30% de lo que hemos visto históricamente.
Teniendo en cuenta las causas de este problema, así como las herramientas disponibles para evitarlo nuevamente, salve el día. Entonces, al menos, espero que comprender los matices de estos desafíos ayude a alguien a evitar algo del dolor que logramos con Pleasant Entry.

